지도를 이용한 시각화 진행
이제 지도를 불러와서 시각화를 진행해보자. 지도를 이용한 시각화는 Folium library를 활용해야 한다.
그런데 우리는 지금 서울시 데이터만 가지고 있기 때문에 서울시 지도만 따로 뽑아서 사용할 것이다.
서울시 지도 데이터는 폴더에 'skorea_municipalities_geo_simple.json' 파일로 저장 되어 있다.
우선 Folium library를 다운로드 시키자.
!pip install folium==0.5.0코드를 실행시키고 마지막 줄에 Successfully가 뜨면 성공이다.
그리고 우리는 json 파일을 열기 때문에 json을 import 해주자
import json
geo_path = 'skorea_municipalities_geo_simple.json'
geo_str = json.load(open(geo_path, encoding='utf-8'))open 함수로 파일명을 읽어서 열고, load로 json 파일을 열어준다. 추가적으로 저장할때는 dump를 사용한다.
geo_str 코드를 실행시키면 다음과 같이 나오게 된다.

딕트값 안에 리스트 값이 들어있는 형식이다.
우리가 원하는 행정구역 명은 features라는 키값 안에 [0]번째 리스트 열에 있는 값 안에 id라는 키값 안에 행정구역명이 들어있다. 이렇게 시각화가 어렵다.
이때 알아두면 좋은 함수가 prnt 함수이다.
!pip install pyprnt==2.3.3
from pyprnt import prnt우선 다운로드 시키고 import를 해주자.
그 다음 print( ) 함수를 작성하듯이 코드를 작성해주면 된다.
prnt(geo_str, truncate=True, width=60)
이때, truncate는 출력값을 요약해주는 것이고, width는 블록간의 간격이다.
안해줘도 상관 없지만 안하면 시각화가 조금 힘들다.
이제 지도 위에 구별로 살인사건 발생 건수를 기준으로 시각화를 진행해보자.
import folium다시 folium를 import 해주자.
map = folium.Map(location=[37.5502, 126.982], zoom_start=11, tiles='Stamen Toner')
map| 함수명 | 설명 |
| Map | folium에 내장된 지도 기능을 사용한다는 뜻 |
| location | 지도의 처음 위치 |
| zoom_start | 낮은 값 = 시야가 넓어짐, 높은 값 = 시야 좁아짐 |
| tiles | 지도 종류 |
tiles 값에 Stamen Toner를 쓰면 지도가 심플하게 나오고, Stamen Terain을 쓰면 위성지도가 나오게 된다. 지도 종류를 선택하는 코드이다.

이렇게 지도를 가져왔으니 살인발생 데이터를 합쳐야 한다. 살인 발생 데이터가 들어있는 데이터 프레임은 gu_df에 있다.
gu_df
map = folium.Map(location=[37.5502, 126.982], zoom_start=11, tiles='Stamen Toner')
map.choropleth(geo_data = geo_str,
data = gu_df['살인'],
columns = [gu_df.index, gu_df['살인']],
fill_color = 'PuRd',
key_on = 'feature.id')| 함수명 | 설명 |
| choropleth | 지도 위에 행정구역별로 나눠서 데이터값을 그림으로 표현 |
| geo_data | 행정구역별 위도, 경도 값 |
| fill_color | polygon 색깔 |
| key_on | 행정구역 명칭 geo_str의 feature type에 있는 id에 행정구역명이 있다는 뜻 |
| columns | [행정구역 명칭, polygon 기준 열] |
| data | 시각화의 대상이 되는 열을 다시 한번 언급 |
geo_data에는 서울시 행정구역별로 polygon을 그려줄 위도, 경도값을 알려줘야 한다. 여기서는 geo_str을 넣어주었다.
중요한것은 data와 columns이다. 우선, columns에는 gu_df 데이터프레임의 2개의 열을 리스트로 묶어서 보내줘야 한다.
첫번째는 행정구역명이 들어 있는 열, 두번째는 polygon을 그릴때 기준이 되는 열

이때, 행정구역명은 gu_df의 인덱스열에 있으므로 인덱스열을 보내주고, 기준열은 살인열을 보내주면 된다.
그리고 data에서 시각화의 대상이 되는 열을 다시 한번 언급해주면 된다.

인구수 고려한 것으로 교체
이때, gu_df 데이터프레임은 인구수를 고려하지 않은 것이므로, 인구수를 고려한 데이터 프레임으로 다시 교체해준다.
인구수를 고려한 데이터프레임은 crime_ratio이다.

map = folium.Map(location=[37.5502, 126.982], zoom_start=11, tiles='Stamen Toner')
map.choropleth(geo_data = geo_str,
data = crime_ratio['전체발생비율'],
columns = [crime_ratio.index, crime_ratio['전체발생비율']],
fill_color = 'PuRd',
key_on = 'feature.id')
map
경찰서의 검거율을 기준으로 지도에 시각화 진행
이제 경찰서마다 검거율을 지도에 시각화 하는 방법을 알아보자.
경찰서가 있던 데이터 프레임은 처음 데이터프레임인 df이다.
df
여기서 경찰서의 위치는 google cloud에 '서울00경찰서'라는 경찰서 이름을 보내주면 주소와 위도 경도 값을 보내준다.
그러기 위해서는 일단 00서를 서울00경찰서라고 이름을 바꿔줘야 한다.
우선 '계' 행은 필요 없으니 삭제해준다.
df.drop([0])
station_name = []
for name in df['관서명']:
station_name.append('서울'+str(name[:-1])+'경찰서')
station_name
이때, name[:-1]을 자세히 알아보면 중부서[:-1]이라는 코드이다. 실행시키면 출력값은 중부라고 나온다.
df['경찰서'] = station_name새로운 열이 df에 추가 되었다. 이제 검거율을 구해서 검거율의 값을 원의 지름으로 하는 시각화를 진행하도록 하자.
df['검거율'] = df['소계(검거)']/df['소계(발생)']*100
df.head()
이때, 검거율의 최솟값은 64이고 최댓값은 80이다. 이 말은 원의 크기 차이가 얼마 나지 않아 시각화가 나쁘다는 뜻이다.
그러면 최솟값을 1로 하고, 최댓값을 100으로 하는 min-max 알고리즘을 진행하자.
계산 코드는 솔직히 몰라도 된다. 나중에는 그냥 최솟값과 최댓값을 대입하면 알아서 min-max 해주는 함수가 있기 때문이다.
def reRange(x, oldMin, oldMax, newMin, newMax):
return (x - oldMin)*(newMax - newMin) / (oldMax - oldMin) + newMin
df['점수'] = reRange(df['검거율'], min(df['검거율']), max(df['검거율']), 1, 100)
이제 google에서 경찰서별 위도와 경도 값을 받아들일 모든 준비가 끝났다.
이제 jupyter notebook에서 goolge maps의 geocoding API를 쓸 준비를 하자.
!pip install googlemaps==4.6.0google maps를 설치하자.
import googlemaps
gmaps = googlemaps.Client(key="ㅁㅁㅁㅁㅁㅁㅁㅁㅁㅁㅁㅁㅁㅁㅁㅁㅁㅁㅁ")여기에는 Client가 나만의 key 값으로 googlemaps에 들어가도록 해줘야 한다. key 값은 유출되면 내 모든 정보를 털릴수도 있으니 주의하자.
우선, '서울강남경찰서'의 정보를 알려달라고 해보자.
tmpMap = gmaps.geocode('서울강남경찰서', language="ko")gmaps에 있는 geocode를 사용해서 '서울강남경찰서'의 정보를 찾는다는 뜻이다.

여러가지 정보가 있는데 우리가 유심히 봐야하는 정보는 4가지이다.
| formatted_address | 대한민국 서울특별시 강남구 삼성동 테헤란로113길 12 |
| location | {'lat': 37.511274, 'lng': 127.0665719} |
| types | ['establishment', 'point_of_interest', 'police'] |
| viewport | 해당 위도에 있는 경찰서를 지도의 정가운데에 놓고 싶을때 쓰는 것 |
여기서 위도와 경도값을 알려면
tmpMap[0].get('geometry')['location']이렇게 코드를 쓰면 되는데, 나중에 for문을 돌릴때는 복잡하다.
tmpMap[0]의 출력값은 다음과 같다.

여기서 geometry 키 값을 가져오는 코드인 tmpMap[0].get('geometry')를 쓰면 다음과 같이 출력된다.

이제 location을 불러오는 코드인 tmpMap[0].get('geometry')['location']를 붙히면 다음과 같다.

tmpLoc = tmpMap[0].get('geometry')
tmpLoc['location']이제 df 데이터 프레임에 위도 값과 경도 값을 넣어주자.
lat = [ ]
lng = [ ]
for name in df['경찰서']:
tmpMap = gmaps.geocode('name', language="ko")
tmpLoc = tmpMap[0].get('geometry')
lat.append(tmpLoc['location']['lat'])
lng.append(tmpLoc['location']['lng'])
df['lat'] = lat
df['lng'] = lng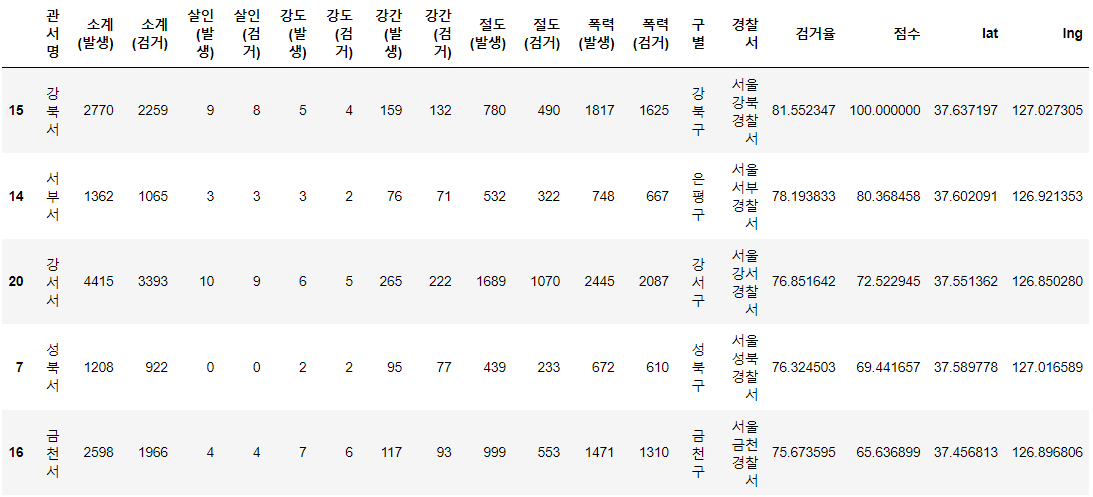
df 데이터 프레임에서 우리가 사용할 열은 index열, 점수열, lat열, lng열이다.
위도와 경도 값을 데이터프레임에서 뽑아내는 방법은 다음과 같다.
df['lat'][15] / df.at[15, 'lat']
37.637197이제 시각화를 진행하자.
map = folium.Map(location=[37.5502, 126.982], zoom_start=11)
for n in df.index:
folium.CircleMarker ([df['lat'][n], df['lng'][n]],
radius=df['점수'][n]*0.5, # circle 의 크기를 결정
color='#3186cc', fill=True, fill_color='#3186cc').add_to(map)
map| 함수명 | 설명 |
| CircleMarker | 지도에 원을 그린다는 함수 |
| [ df['lat'][n], df['lng'][n] ] | 경찰서의 위도와 경도 값 |
| radius=df['점수'][n]*0.5 | 원의 크기 |
| color | 원 테두리 색깔 |
| fill | 원을 채울것이냐 |
| fill_color | 원의 색깔 |
| add_to(map) | 지도 위에 올려주는 작업 |

'서울시 범죄현황 통계자료 분석 및 시각화' 카테고리의 다른 글
| 05. 서울시 범죄현황 통계자료 분석 및 시각화 (0) | 2023.06.30 |
|---|---|
| 04. 서울시 범죄현황 통계자료 분석 및 시각화 (1) | 2023.06.30 |