이제부터 Jupyter Notebook으로 제대로 된 프로젝트를 시작하겠다.
프로젝트는 '서울시 범죄 현황 통계자료를 분석하고, 시각화'를 하는 것이다.
import numpy as np
import pandas as pd
import seaborn as sns
from matplotlib import font_manager, rc
우선 가장 기본적인 세팅을 해주자. 마지막 matplotlib은 한글 폰트를 위한 것인데, 굳이 외워서 안써도 된다.
그리고 서울시 범죄현황 파일은 Jupyter Notebook과 같은 폴더 안에 있어야 쉽다.
이제 파일을 불러오자.
df = pd.read_excel('관서별 5대범죄 발생 및 검거.xlsx')
엑셀 파일이기 때문에 read_excel 함수를 사용한다.

파일을 불러왔으니 파일에게 간단한 질문들을 해보자.
df.head( ) / .tail( ) / .describe( ) / .info( )
df.describe( )
데이터 프레임의 평균값, 중간값, 최댓값 등등을 보여주는 것이다. 하지만 지금은 계 행이 있기 때문에 터무니 없는 수치가 나올 것이다.

그렇기 때문에 계 행을 삭제 후 다시 describe로 출력한다.
df.drop['계']
df.describe()
1. 경찰서 명(00구)을 행정구역 명(00구)으로 바꾸는 작업
이렇게 데이터 프레임을 둘러 보았으니 시각화 하기 쉽게 경찰서를 구별로 정리하자.
구별로 정리해야 지도 이미지에 넣었을 때 시각화가 쉽다.
웹크롤링을 사용해서 OO경찰서를 OO구로 바꿀 수 있는데, 별로 없으니 그냥 작성하자.
police_to_gu = {'서대문서': '서대문구', '수서서': '강남구', '강서서': '강서구', '서초서': '서초구',
'서부서': '은평구', '중부서': '중구', '종로서': '종로구', '남대문서': '중구',
'혜화서': '종로구', '용산서': '용산구', '성북서': '성북구', '동대문서': '동대문구',
'마포서': '마포구', '영등포서': '영등포구', '성동서': '성동구', '동작서': '동작구',
'광진서': '광진구', '강북서': '강북구', '금천서': '금천구', '중랑서': '중랑구',
'강남서': '강남구', '관악서': '관악구', '강동서': '강동구', '종암서': '성북구',
'구로서': '구로구', '양천서': '양천구', '송파서': '송파구', '노원서': '노원구',
'방배서': '서초구', '은평서': '은평구', '도봉서': '도봉구'}이렇게 dict 값을 생성해 두자.
df['구별'] = df['관서명'].apply(lambda x : police_to_gu.get(x, '구 없음'))
get 함수 없이 dict 함수를 사용해도 된다.
dict = {'a':1, 'b':2, 'c':3}
dict['d']
하지만 get 함수를 사용하지 않으면 key 값이 없을 때 바로 key error를 발생시킨다.
dict = {'a':1, 'b':2, 'c':3}
dict.get('d', 'null')
get 함수를 쓰면 key 값이 없을 때, 'null'을 출력시킨다.
이제 '구별'이라는 열을 인덱스열로 바꾸자.
df.set_index('구별')

추가적으로 인덱스열을 일반열로 바꾸는 것은 reset만 추가하면 된다.
df.reset_index()그런데 '구별'열을 인덱스 열로 바꾼 데이터프레임을 보면 중구, 종로구 등등 두개가 같이 있는 것을 확인할 수 있다.
이것은 단순히 경찰서를 구로 바꾸고 인덱스열로 바꿨기 때문이다.
pivot table을 사용해 합쳐야 한다.
gu_df = pd.pivot_table(df, index='구별', aggfunc=np.sum)
같은 구의 경우에는 sum을 통해 더해준다고 작성했다.

이 데이터 프레임에 더이상 '구 없음' 이라는 행은 필요가 없다. 삭제하도록 하자.
gu_df.drop('구 없음')

이제 범죄별 검거율을 계산하고 검거 건수 열을 모두 삭제하자.
gu_df['강간검거율'] = gu_df['강간(검거)']/gu_df['강간(발생)']*100
gu_df['강도검거율'] = gu_df['강도(검거)']/gu_df['강도(발생)']*100
gu_df['살인검거율'] = gu_df['살인(검거)']/gu_df['살인(발생)']*100
gu_df['절도검거율'] = gu_df['절도(검거)']/gu_df['절도(발생)']*100
gu_df['폭력검거율'] = gu_df['폭력(검거)']/gu_df['폭력(발생)']*100
gu_df['검거율'] = gu_df['소계(검거)']/gu_df['소계(발생)']*100이 코드를 보면 알다시피 DataFrame의 열마다 사칙연산은 바로바로 적용이 된다.
검거율 = 검거 횟수 / 발생 건수 * 100
del gu_df['강간(검거)']
del gu_df['강도(검거)']
del gu_df['살인(검거)']
del gu_df['절도(검거)']
del gu_df['폭력(검거)']
del gu_df['소계(발생)']
del gu_df['소계(검거)']이렇게 같은 코드를 수정해야 할 때는 멀티 커서 기능을 사용할 수 있다.
Ctrl+커서 이동을 하면 멀티 커서로 동시에 수정이 된다.

이때, 검거율이 100%를 넘는 값이 있다. 이런 현상이 발생하는 이유는 예전에 발생한 사건을 이번년도에 잡아서 발생 건수와 검거 건수가 역전된 상황이다.
검거율이 100%가 넘는 값을 100으로 바꾸는 작업을 하자. 나중에 시각화 할 때 이쁘게 보이기 위해서다.
for문과 if문을 쓰는 방법과 한줄로 사용하는 방법이 있다.
columns = ['강간검거율', '강도검거율', '살인검거율', '절도검거율', '폭력검거율']
gg = gu_df[columns]
for a, b in gg.iterrows():
for i in columns:
if b[i]>100:
gu_df.at[a, i]=100

인덱스열과 100%가 넘는 열을 표로 만들어 둔 것이다.
for문을 통해 표 하나하나 value 값을 뽑아 내야 한다.
이때 필요한 함수가 .iterrows()이다.
for i in gu_df_rate.iterrows():
print(i)
print("______")출력값은 다음과 같이 나오게 된다.

행의 이름, dict 형식으로 (열의 이름+열의 value 값) 2가지로 나뉘어서 출력된다.
for a, b in gu_df_rate.iterrows():
print(a)
print("__________")
print(b)
print("+++++++++")
우리는 열의 value 값이 필요하다. dict 형식으로 key 값을 호출하면 열의 value 값은 자동으로 나오게 된다.
이때, columns가 필요하다.
for a, b in gu_df_rate.iterrows():
for i in columns:
print(b[i])b에는 { '강도 검거율' = '88.234', '강간 검거율' = '13.3452', ~~ } 이렇게 있는데, columns 값을 하나씩 넣으면 value 값은 자동으로 나오게 된다.

이제 value 값을 뽑았으니 이것이 100보다 큰 것들만 필터링 해주자.
for a, b in gu_df_rate.iterrows():
for i in columns:
if b[i]>100:또 중요한 함수가 등장한다.
필터링 해주었으니 100보다 큰 것들은 다시 gu_df 데이터프레임에 100으로 넣어야 한다.
이때 행의 이름, 열의 이름을 제공해주고 .at 함수를 쓰면 쉽게 적용이 된다.
아까 행의 이름은 첫번째 for문의 a가 행의 이름이다. 그리고 열의 이름은 100보다 큰 열이므로 두번째 for문의 i 값을 넣어주면 된다.
for a, b in gu_df_rate.iterrows():
for i in columns:
if b[i]>100:
gu_df.at[a,i]=100이제 변수명만 바꿔주면 앞서 소개한 코드와 동일하다.
그런데 이 코드를 한줄로 끝내는 방법이 있다.
gu_df[gu_df[['강간검거율', '강도검거율', '살인검거율', '절도검거율', '폭력검거율']]>100]=100
gu_df[['강간검거율', '강도검거율', '살인검거율', '절도검거율', '폭력검거율']] > 100는
100%가 넘는 열에서 100이 넘는 것들을 찾아서 True, False로 표현해주는 것이다.
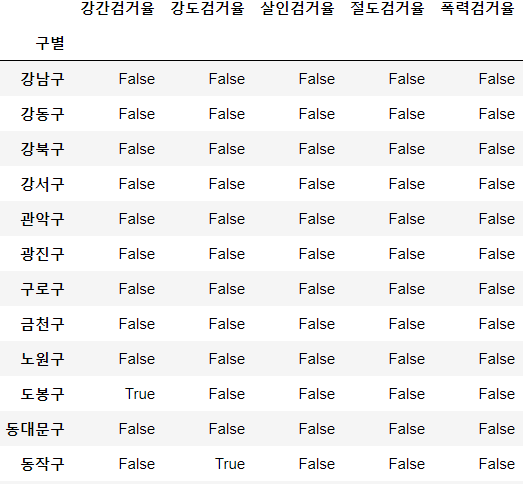
이 코드를 다시 gu_df로 감싸면 False 값은 NaN 값이 되고, True 값은 그대로 표현이 된다.
gu_df[gu_df[['강간검거율', '강도검거율', '살인검거율', '절도검거율', '폭력검거율']]>100]
이렇게 표현된 데이터프레임에 =100을 해주면 NaN 값이 아닌 값은 모두 100으로 적용이 된다.
gu_df[gu_df[['강간검거율', '강도검거율', '살인검거율', '절도검거율', '폭력검거율']]>100]=100
위와 같은 방식으로 filtering이 가능하다.
주로 and 연산, or 연산, not 연산이 주를 이룬다.
Ex) 살인사건 발생 건수가 7건이 넘는 지역구를 찾아내라.
gu_df[gu_df['살인(발생)']>7]Ex) 살인 발생 건수가 7건이 넘고, 폭력 건수가 2000건을 넘는 지역구를 찾아라.
gu_df[(['살인(발생)'] > 7) & (['폭력(발생)'] > 2,000)]
중요한 것은 ( )로 묶고, and로 안쓰고 &로 써야 한다는 것이다.
Ex) 살인 발생 건수가 7건이 넘거나 폭력 발생 건수가 2000건 넘는 지역구를 찾아라.
gu_df[(['살인(발생)'] > 7) | (['폭력(발생)'] > 2,000)]
Ex) 살인 발생 건수가 5건을 넘지 않는 지역구를 찾아라.
gu_df [ ~( ['살인(발생)] > 5 ) ]
gu_df[~(['살인(발생)] > 5)]not의 비트 논리 연산자는 ~이다.
전에 설명한 cotains 함수도 사용이 가능하다.
gu_df [ gu_df['경찰서 이름'].str.contains('특정 문자열') ]
gu_df[gu_df['경찰서 이름'].str.contains('특정 문자열')]
다시 데이터 프레임을 보면 도봉구의 살인 검거율이 NaN이다. 이것은 살인 발생 건수가 0이기 때문에 발생한 현상이다.
살인 발생 건수가 0인 지역구를 추려내는 코드는 다음과 같다.
gu_df[gu_df['살인(발생)'] == 0]
살인 검거율의 결측치를 NaN으로 두지 말고 100으로 두자. 검거를 못한 것ㅇ 아니라 없어서 안한거기 때문이다.
gu_df['살인검거율']=gu_df['살인검거율'].fillna(100)
이제 OO(발생)이라는 것이 필요 없으니 열의 이름을 바꿔주자.
gu_df.rename(columns = {'강간(발생)':'강간',
'강도(발생)':'강도',
'살인(발생)':'살인',
'절도(발생)':'절도',
'폭력(발생)':'폭력'}, inplace=True)
gu_df.rename(columns = {'강간(발생)':'강간',
'강도(발생)':'강도',
'살인(발생)':'살인',
'절도(발생)':'절도',
'폭력(발생)':'폭력'}, inplace=True)
이제 이 5대 범죄, 5대 범죄 검거율 데이터가 담긴 데이터프레임에 각 구별 인구수 데이터가 담긴 또 다른 데이터 프레임을 합치는 작업을 해보자.

데이터 프레임 A와 B가 있다고 가정하면, 두 데이터 프레임을 합치는 방법은 3가지가 있다.
첫번째는 가장 많이 사용하고, 활용도가 높은 방식이다.
A.join(B)
이 방식의 가장 큰 장점은 인덱스열의 이름이 서로 뒤죽박죽 섞여있어도 알아서 잘 찾아서 배치가 된다는 것이다.
만약 A의 인덱스열 순서는 강서구, 서대문구, 마포구, 도봉구로 되어있고 B의 인덱스열 순서는 도봉구, 마포구, 서대문구, 강서구로 되어 있어도 A의 인덱스열에 맞춰 강, 서, 마, 도 순서로 B의 데이터가 합쳐진다.
하지만 인덱스열이 서로 동일해야 가능한 방법이다.
두번째는 인덱스열이 서로 맞지 않는 파일일때 권장하는 방법이다. 기준열을 코드에서 정해주기 때문이다.
pd.merge(A, B, left_on='구별', right_on='구 이름', how='inner')
데이터 프레임 A가 왼쪽에 B가 오른쪽에 있으므로 A는 left_on='구별', B는 right_on='구 이름'이다.
이 말은 A와 B의 기준열을 정해주고 시작한다는 뜻이다.
중요한것은 how='inner' 인데, inner은 한국어로 교집합이라는 뜻이다.
만약 A의 기준열에는 a, b, c가 있고 B의 기준열에는 a, c, e만 있다고 가정해보자.
그러면 a와 c에는 B의 데이터 값이 붙고, b에는 NaN 즉, 결측치가 붙는다. 그리고 e는 사라지게 된다.
세번째는 주로 좌우로 붙이는 것이 아니라, 위아래로 합쳐야 할 때 사용한다.
예를 들어 위에서부터 아래로 2021~2023년의 데이터가 내려간다고 생각하자. 그때 그냥 붙히는 것이다.
pd.concat([A, B], axis=???)
이제 인구수 데이터를 불러와보자.
인구수 데이터가 있는 파일은 csv 파일이다.
popul_df = pd.read_csv('pop_kor.csv', encoding='utf-8')이때, 인덱스열을 바로 지정할 수 있다.
popul_df = pd.read_csv('pop_kor.csv', encoding='utf-8', index_col='구별')
이제 가장 대중적인 방법인 첫번째 방법으로 두개의 데이터 프레임을 합쳐보자.
gu_df = gu_df.join(popul_df)
'서울시 범죄현황 통계자료 분석 및 시각화' 카테고리의 다른 글
| 06. 서울시 범죄현황 통계자료 분석 및 시각화 (0) | 2023.07.02 |
|---|---|
| 05. 서울시 범죄현황 통계자료 분석 및 시각화 (0) | 2023.06.30 |