우리가 영어로 된 text data를 전처리 하고자 할때는 nltk라는 라이브러리를 사용했다.
그런데 nitk는 한국어를 지원하지 않는다. 그래서 한글용 라이브러리인 Konlpy를 사용한다.
이건 좋긴 한데, 설치가 매우 까다롭다.
from konlpy.tag import Okt
tokenizer = Okt()
tokens = tokenizer.pos("아버지 가방에 들어가신다.", norm=True, stem=True)
print(tokens)[('아버지', 'Noun'), ('가방', 'Noun'), ('에', 'Josa'), ('들어가다', 'Verb'), ('.', 'Punctuation')]테스트를 해보면 다음과 같다.
nltk는 nltk.word_tokenizer(문장 입력) >> nltk.pos_tag(token된 문장)을 했는데,
Konlpy는 tokenizer와 pos_tag 작업을 동시에 진행시켜준다.
이때, norm과 stem이 활성화 되어있다.
norm == 정규화(normalization)
'한국어를 처리하는 예시입니닼ㅋㅋㅋ '-> '한국어를 처리하는 예시입니다ㅋㅋ'
텍스트 데이터를 정갈하게 다듬어준다.
stem == 어근화(stemming)
식물의 줄기라는 뜻 / 사전형 단어로 바꿔줌. / lemma~과 같은 기능
한국어를 처리하는 예시입니다 ㅋㅋ -> 한국어Noun, 를Josa, 처리Noun, 하다Verb, 예시Noun, 이다Adjective, ㅋㅋKoreanParticle
이제 불용어(한글자로 된 단어와 원하지 않은 단어)를 제거한 뒤, 각 단어의 출현 빈도수를 세주는 작업을 해주자.
raw_pos_tagged[ ('인천', 'Noun'),
('테크노', 'Noun'),
('파크', 'Noun'),
('로고', 'Noun'),
('.', 'Punctuation'),
('(', 'Punctuation'),
('이미지', 'Noun'),
('=', 'Punctuation'),
('인천', 'Noun'),
('테크노', 'Noun')]word = []
stopwords = [',', '을', '를', ~]
for i in raw_pos_tagged:
if i[1] not in ["Josa", "Eomi", "Punctuation", "Foreign"]:
if (len(i[0])!=1) & (i[0] not in stopwords):
word.append(i[0])['인천',
'뉴시스',
'루비',
'기자',
'인천',
'테크노']이제 출현 횟수를 세주는 방법은 두가지가 있다.
word_count = {}
for i in word:
if i not in word_count:
word_count[i] = 1
else:
word_count[i] +=1from collections import Counter
word_count = Counter(word)
word_dic = dict(word_count)
word_dic{'인천': 15,
'뉴시스': 13,
'루비': 2,
'기자': 20,
'테크노': 3,
'파크': 3,
'로고': 1]이것을 출현빈도 순으로 정렬을 해준다.
word_sort = sorted(word_dic.items(), key = lambda x : x[1], reverse = True)이때, word_dic.items()는 dict값을 tuple로 꺼내서 출현 횟수를 꺼낼 수 있게 해주는 것이다.
word_dic.items()[1] >> 출현 횟수만 뽑아진다.
dict_items([('인천', 15), ('뉴시스', 13), ('루비', 2), ('기자', 20), ('테크노', 3), ('파크', 3), ('로고', 1),상위 50개의 단어를 출력하는 코드는 다음과 같다.
for i in word_sort[:50]:
print(i[0](i[1]))데이터(538) 분석(252) 서비스(154) 빅데이터(115) 활용(102) 기업(96) 기술(93) 개발(89)
단어 등장 빈도를 시각화 해보자.
import nltk
import matplotlib
import matplotlib.pyplot as plt
from matplotlib import font_manager, rc
font_name = matplotlib.font_manager.FontProperties(fname="C:/Windows/Fonts/malgun.ttf").get_name() # NanumGothic.otf
matplotlib.rc('font', family=font_name)불용어를 제거한 단어 사전을 가져오자.
word
['인천', '뉴시스', '루비', '기자', '인천', '테크노', '파크', '로고' ~]word_count = nltk.Text(word)
plt.figure(figsize = (15, 5))
word_count.plot(50)nltk.Text 함수가 자동으로 단어 갯수를 세주고, 정렬까지 해준다.
plot(50)은 상위 50개의 단어로 그래프를 그려준다는 뜻이다.
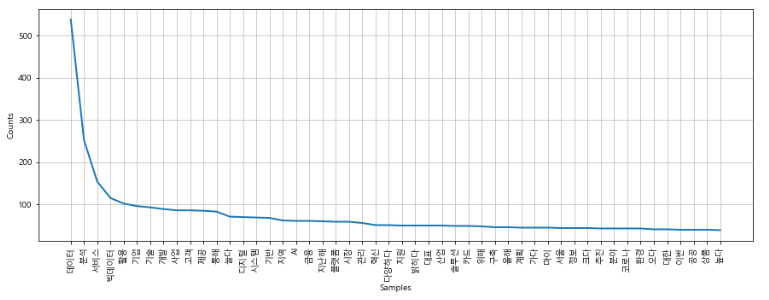
이때, 줄그래프 말고 막대 그래프로 그릴수 있다.
막대그래프는 바로 그릴 수 없어서 nltk의 FreqDist 함수를 거친 뒤, DataFrame에 데이터를 담고 막대 그래프로 표현한다.
FreqDist 함수는 단어의 등장 빈도를 담는 class이다.
word
['인천', '뉴시스', '루비', '기자', '인천', '테크노', '파크', '로고' ~]word_frequency = nltk.FreqDist(word)FreqDist({'데이터': 538, '분석': 252, '서비스': 154, '빅데이터': 115, '활용': 102, '기업': 96, '기술': 93, '개발': 89, '사업': 86, '고객': 86, ...})여기서 key값이나 value값만 뽑을 수 있다.
word_frequency.keys() / .values()이제, 데이터 프레임에 index 값은 key값으로 넣고, data 값은 value 값으로 넣는 작업을 하자.
df = pd.DataFrame(list(word_frequency.values()), word_frequency.keys())
열의 이름도 넣을 수 있다.
df = pd.DataFrame({'출현 빈도' : list(word_frequency.values())})
df.index = word_frequency.keys()
이제 내림차순 정렬 후, 상위 50개의 단어만 가져오는 작업을 해줍니다.
df_sort = df.sort_values([0], ascending=False)
df_sort[:50]df의 value 값으로 정렬을 하고, 0번째 열을 기준으로 정렬한다는 뜻입니다.
이제 막대그래프로 그려줍니다.
df_sort.plot(kind='bar',legend=False, figsize=(15,5)
plt.show()그래프 형태는 많이 있습니다.
이제 WordCloud를 만들어 봅시다.
WordCloud란, 많이 사용한 단어는 크게, 적게 사용한 단어는 작게 만드는 것입니다.
WordCloud를 사용하기 위해서는 WordCloud library와 각 단어의 출현 빈도수가 담긴 dict 값이 필요합니다.
from wordcloud import WordCloud
import matplotlib.pyplot as plt
from PIL import Image
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inlineword_dic
{'인천': 15, '뉴시스': 13, '루비': 2, '기자': 20, '테크노': 3, '파크': 3, '로고': 1, '이미지': 12, ~ }이제 WordCloud를 만들면 됩니다.
WordCloud 코드를 만들때, WordCloud 함수는 도화지라고 생각하면 편합니다.
도화지 위에 내가 원하는 그림을 자유롭게 그리면 됩니다.
word_cloud = WordCloud(font_path="C:/Windows/Fonts/malgun.ttf",
width=2000, height=1000,
background_color='white')
word_cloud.generate_from_frequencies(word_dic)이것이 가장 기본적인 WordCloud 코드입니다.
font_path는 어떤 폰트를 사용하는지 물어보는 것입니다.
width=2000, height=1000는 jupyter notebook에 표현되는 크기가 아니라 컴퓨터로 저장했을때 해상도를 의미합니다.
해상도는 높으면 화질이 선명해지지만 WordCloud를 그리는데 시간이 오래걸리게 됩니다.
prefer_horizontal= 1.0 라는 코드는 글씨가 가로로만 작성되게 합니다.
word_cloud.generate_from_frequencies(word_dic)는 frequencies 출현 빈도 순서로 (word_dic)의 데이터를 사용해서
word_cloud를 generate 생성해달라는 코드입니다.
이제 실제 WordCloud를 그리는 코드입니다.
plt.figure(figsize=(15,15))
plt.imshow(word_cloud)
plt.axis("off")
plt.tight_layout(pad=0)
plt.show()figure(figsize=(15,15))는 화면에서 보여지는 크기를 수정할 수 있는 코드입니다.
imshow(word_cloud)는 image show의 약자입니다. word_cloud를 화면에 보여주는 실질적인 코드입니다.
.axis()를 on으로 하면 가로 세로 축의 값을 보여줍니다.
tight_layout(pad=0)는 여백을 없애달라는 코드입니다. strip()함수와 비슷합니다.

바탕화면 색깔은 검은색으로, 최대 단어 갯수는 50개, 최대 폰트 사이즈는 100으로 수정해보겠습니다.
word_cloud = WordCloud(font_path="C:/Windows/Fonts/malgun.ttf",
width=2000, height=1000,
max_words = 50,
max_font_size = 100
background_color='Black').generate_from_frequencies(word_dic)
plt.figure(figsize=(15,15))
plt.imshow(word_cloud)
plt.axis("off")
plt.tight_layout(pad=0)
plt.show()
그림 위에 텍스트 데이터를 올려둘 수 있습니다.
우선 그림 파일부터 열어줍니다.
Image.open("python_mask.jpg")
이제 이 이미지 파일을 배열로 바꾼 뒤, WordCloud에게 넘겨 줘야 합니다.
python_coloring = np.array(Image.open("python_mask.jpg"))
word_cloud = WordCloud(font_path="C:/Windows/Fonts/malgun.ttf",
width=2000, height=1000,
mask=python_coloring,
background_color='white').generate_from_frequencies(word_dic)
plt.figure(figsize=(15,15))
plt.imshow(word_cloud)
plt.axis("off")
plt.tight_layout(pad=0)
plt.show()np.array(Image.open("python_mask.jpg")).shape
(1200, 1200, 3)이때, (1200, 1200)은 이미지 파일의 크기이며, 3은 rgb가 겹친 정도를 말해줍니다.
이 정보가 있어야 rgb 위에 한글 폰트가 올라가게 됩니다.

특정 테두리에 특정 색깔만 지정해줄 수도 있습니다.
이때는 plt.imshow를 수정해주면 됩니다.
from wordcloud import ImageColorGenerator
python_coloring = np.array(Image.open("python_mask.jpg"))
image_colors = ImageColorGenerator(python_coloring)
word_cloud = WordCloud(font_path="C:/Windows/Fonts/malgun.ttf",
width=2000, height=1000,
mask=python_coloring,
background_color='white').generate_from_frequencies(word_dic)
plt.figure(figsize=(15,15))
plt.imshow(word_cloud.recolor(color_func=image_colors), interpolation='bilinear')
plt.axis("off")
plt.tight_layout(pad=0)
plt.show()word_cloud.recolor은 word_cloud를 recolor 다시 칠한다는 뜻입니다.
()안에 다시 칠할 조건이 들어있습니다.
color_func=image_colors는 원본 이미지 색깔에 맞춰서 다시 칠해달라는 뜻입니다.
interpolation='bilinear'는 무시해도 되는데, 세세한 부분을 보안한다는 뜻입니다.
여기서 원본 이미지 색깔 말고 우리가 원하는 색깔을 넣을 수 있습니다.
이때 ()안에 colormap='Blues'와 같이 우리가 원하는 색깔을 넣어주면 됩니다.
다 끝난 뒤 저장은 다음 코드를 사용하면 됩니다.
word_cloud.to_file("word_cloud_completed.png")